파이썬을 활용한 웹 크롤링은 간단하면서도 굉장히 유용하다. 웹 크롤링/웹 스크레핑을 이용하면 특정 웹사이트에서 원하는 정보를 가져오는 반복적인 작업을 자동화 할 수 있다. 마치 데이터 수집 봇을 개발하는 식이다!
실무에 활용될만한 예제를 들어 코딩 초보자도 쉽게 따라할 수 있는 웹 크롤링 입문용 예제를 소개해보겠다.
예제는 하이마트 웹페이지에서 제품명과 가격 정보를 크롤링 해오는게 목표이다.
[정보를 가져오고자 하는 웹사이트의 모습]

[자동 수집된 데이터가 엑셀 파일에 저장된 모습]

파이썬을 일절 사용해본 적 없는 초보자도 쉽게 따라할 수 있도록 포스팅할 계획이니, 어느정도 기초가 있는 사람이라면 얼른 스크롤을 내려 3. 본격 예제 코드 돌려보기 로 가자.
1. 기본 세팅하기 (파이썬 설치)
파이썬 사용에 도움을 주는 아나콘다를 설치한 후 (아나콘다를 설치하면 파이썬은 자동으로 깔린다) 파이썬 언어를 작성하고 코드를 돌릴 수 있는 에디터인 주피터 노트북을 실행할 것이다. 그럼 코드를 돌리기 위한 모든 준비가 완료된다.
아래 사이트에 접속한 후 (새로운 탭으로 열어 설명을 보며 따라해보자)
https://www.anaconda.com/distribution/
Anaconda Python/R Distribution - Free Download
Anaconda Distribution is the world's most popular Python data science platform. Download the free version to access over 1500 data science packages and manage libraries and dependencies with Conda.
www.anaconda.com
스크롤을 살짝 내리면 이런 화면을 마주하게 될텐데 1. 본인이 사용하는 운영체제를 선택한 후 2. Python 버전 3.7을 다운로드하면 된다.
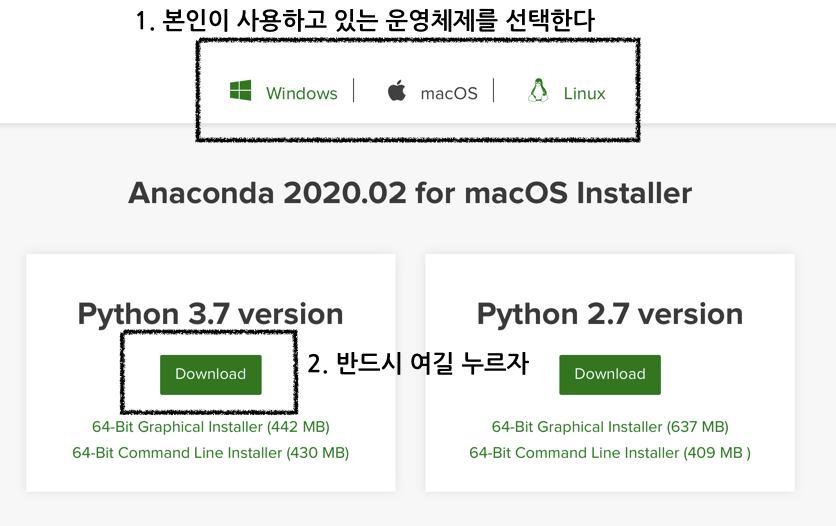
그 이후 뜨는것은 모두 고민 없이 next 만 누르며 다운로드를 진행해준다.
설치 이후 anaconda navigator 라는 앱이 설치되었을 것이다. 실행 시키면 아래와 같은 화면이 뜬다.
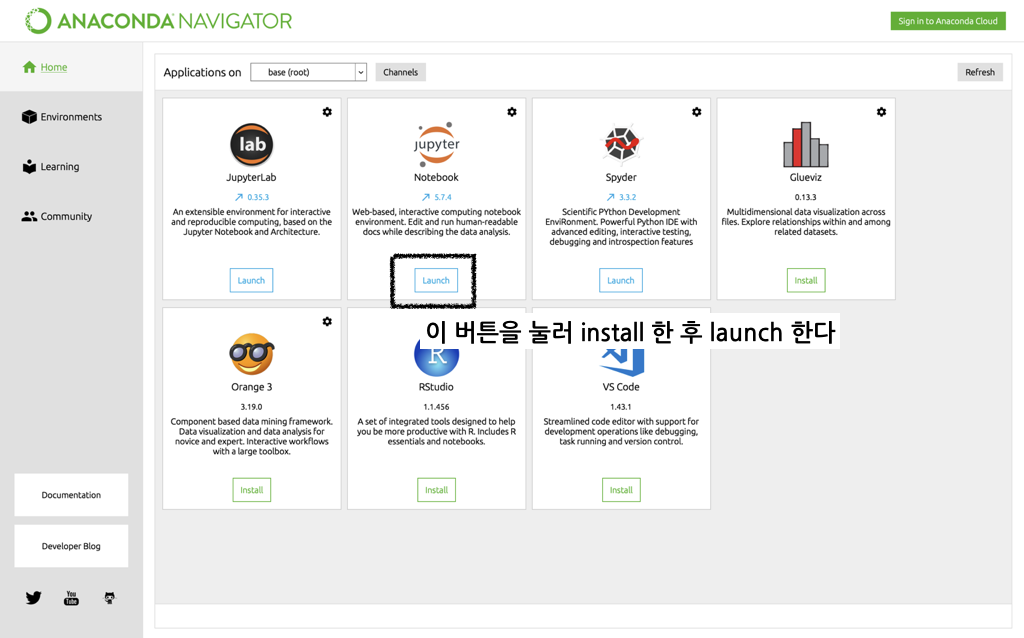
원하는 경로에 주피터노트북 창을 열어준다. 오른쪽 상단의 new 버튼 클릭> python 3 클릭
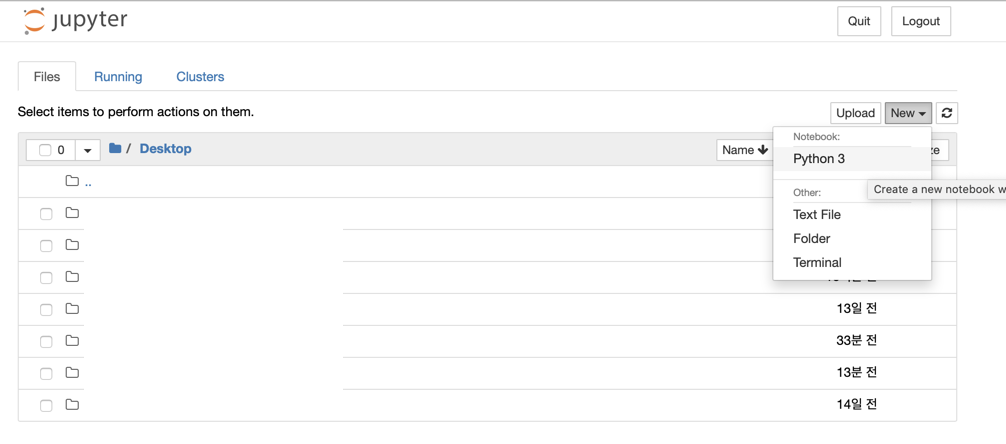
2. 사전 준비하기
한번 돌려서 오류 없이 돌아가는것을 확인하면 이해하는것은 시간문제이다. 두가지 준비사항이 있다.
첫번째, 라이브러리를 설치한다. 정적 크롤링을 도와주는 requests, 동적 크롤링을 도와주는 selenium, html코드를 parsing (쉽게 말해 html코드를 우리가 다루기 쉽게 바꿔주는것) 하는걸 도와주는 bs4 라이브러리를 다운로드해준다.
잠시 아나콘다와 주피터 노트북 창을 닫고, 터미널 혹은 cmd 창을 켜서
pip install requests pip install selenium pip install bs4
각각을 한줄 한줄 입력한다. 이런식으로
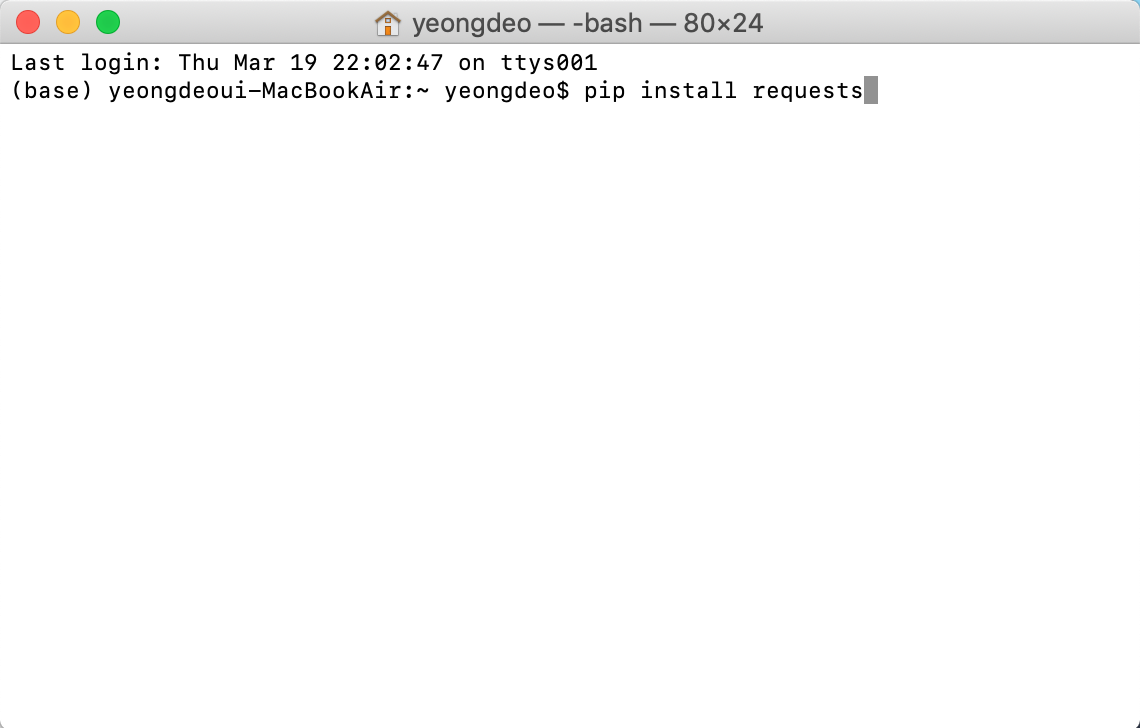
다운로드가 완료되면 다시 아나콘다 네비게이터를 열고 주피터 노트북 창을 켜준다.
두번째, 크롬 드라이버를 설치한다. 설치 방법은 아래 링크를 참고하자.
https://beomi.github.io/2017/02/27/HowToMakeWebCrawler-With-Selenium/
나만의 웹 크롤러 만들기(3): Selenium으로 무적 크롤러 만들기 - Beomi's Tech blog
좀 더 보기 편한 깃북 버전의 나만의 웹 크롤러 만들기가 나왔습니다! Updated @ 2019.10.10. Typo/Layout fix, 네이버 로그인 Captcha관련 수정 추가 이전게시글: 나만의 웹 크롤러 만들기(2): Login with Session Selenium이란? Selenium은 주로 웹앱을 테스트하는데 이용하는 프레임워크다. webdriver라는 API를 통해 운영체제에 설치된 Chrome등의 브라우저를 제어하게 된다. 브라우저를 직
beomi.github.io
3. 본격 예제 코드 한번 돌려보기
import pandas as pd
import requests
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.Chrome('/Users/Username/Desktop/project/chromedriver')
url = 'http://www.e-himart.co.kr/app/display/showDisplayCategory?dispNo=1011030000#pageCount=1@categoryQuery=1011000000!TV/세탁기/건조기:1011030000!세탁기'
driver.get(url)
html = driver.page_source
driver.quit()
soup = BeautifulSoup(html, 'html.parser')
prd_Name = soup.findAll("p", {"class": "prdName"})
prd_name = []
for i in prd_Name:
prd_name.append(i.get_text())
prd_Info = soup.findAll("div", {"class": "priceInfo"})
original_price = []
discount_price = []
n = 0
for i in prd_Info:
if n%2 == 0:
a = i.find_all("strong")[0].get_text()
original_price.append(int(a.replace(',', '')))
n+=1
else:
a = i.find_all("strong")[0].get_text()
discount_price.append(int(a.replace(',', '')))
n+=1
prd_Info2 = soup.findAll("div", {"class": "priceInfo priceBenefit"})
final = pd.DataFrame({'이름': prd_name, '정상가': original_price, '할인가': discount_price})
name = final['이름'].to_list()
final.to_csv('세탁기데이터.csv')
위의 코드를 복사해서 붙여넣는다. 여기서 5번째 줄에 나와있는 아래 경로만 본인의 크롬 드라이버가 설치된 경로로 바꿔주면 된다.
driver = webdriver.Chrome('/Users/Username/Desktop/project/chromedriver')
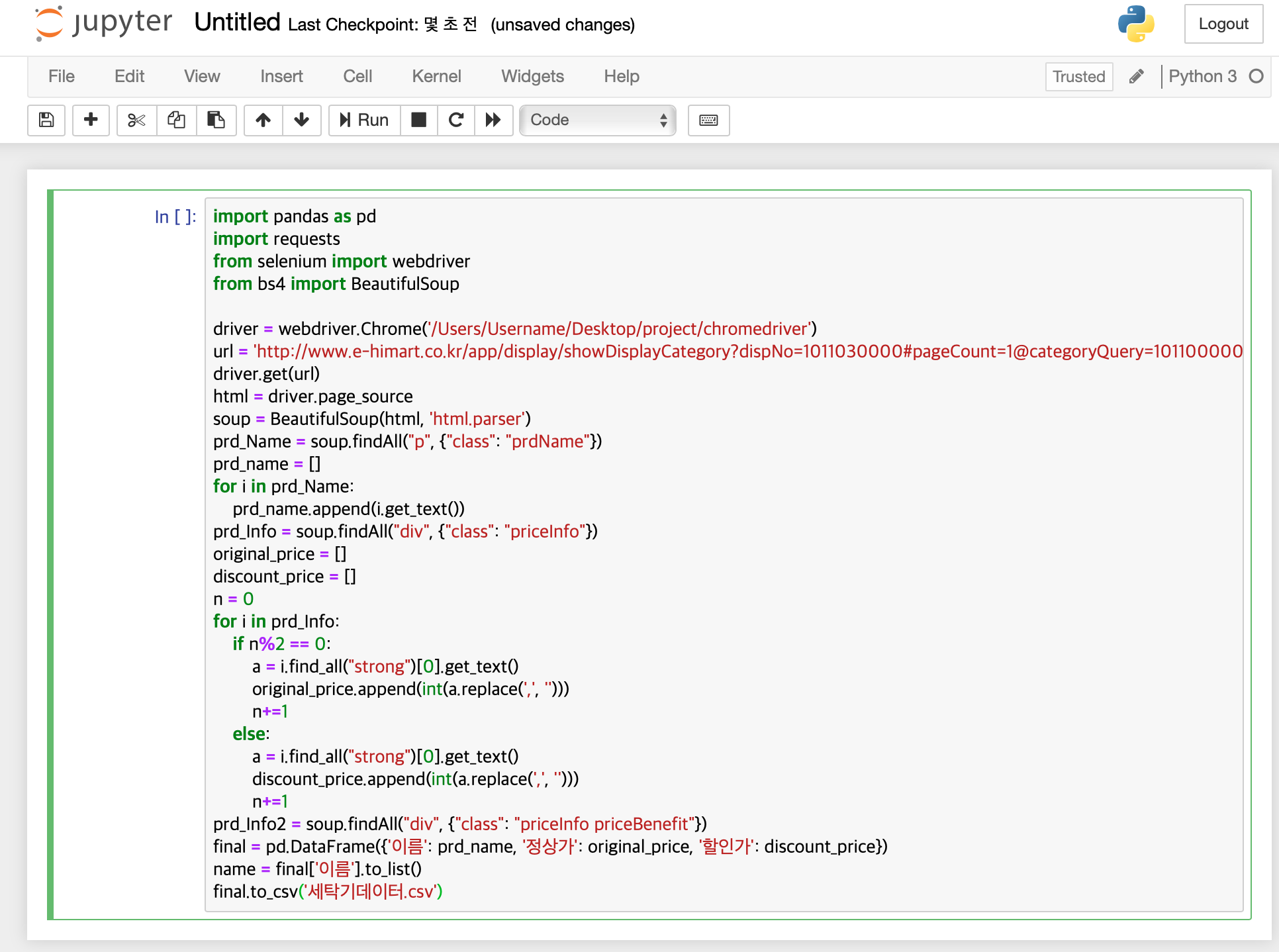
이렇게 복사붙여넣기하고 네모박스안에 커서가 있는 상태로 control+엔터를 누르면 코드가 실행된다. 오류 없이 실행된다면, 저 주피터 노트북이 있는 파일 경로에 세탁기데이터.csv가 생성되었을 것이다.
오늘 포스팅은 여기까지 하고 수요가 있다면 예제코드의 의미를 한줄 한줄 설명하는 포스팅을 해보려고합니다 ^_^.
또 계획하고있는 포스팅은 아래와 같은데 이 중 어떤게 필요한지 댓글 남겨주시면 후속편으로 포스팅해볼게요~
- 홈페이지 내 링크를 타고 타고 들어가면서 크롤링하기
- 반복문을 이용해서 다양한 제품군을 한번에 크롤링하기
- 크롤링 차단을 피하는 방법
- 어제까지 수집한 엑셀파일을 읽어와서 오늘 수집한 데이터를 해당 파일에 추가 저장해서 매일매일 수집하는 방법
- 매일매일 파이썬 실행할 필요 없이 정해진 시간에 코드 돌리도록 설정하는 방법
(+덧)
유튜브 나도코딩이라는 채널을 발견했는데 웹크롤링과 웹스크래핑에 대해 굉장히 친절하고 자세하게 설명합니다.
https://youtu.be/yQ20jZwDjTE
'사업 > python 으로 모든걸 할수있다' 카테고리의 다른 글
| google ortools routing 결과 시각화 (0) | 2020.03.24 |
|---|---|
| 그래프로 보는 순위 영상 만들기 (5) | 2020.03.23 |
| [Corona 19] 전세계 확진자 수 변화 추이 시각화 (0) | 2020.03.14 |
| 웹크롤링과 데이터 시각화로 만들어본 유튜브 데이터의 bar chart race (7) | 2020.03.13 |
| 웹 크롤링 중 일어날 수 있는 오류들 정리 (10) | 2020.03.12 |

